Recent Posts
Implementing Flux with Redux and Firebase for Client-Side Web Applications
I recently began to consider the implementation of a simple “back-end server” application to demonstrate some new features for SDG Systems’ Barcode List Manager application (Barliman)* for Android. Now “back-end server” is in quotes because the data store we were using to share data was Firebase, which means that all that was really required was a client side web application to display the data being pushed up by the Barliman application. Before starting in on the project, I decided to adhere to the Flux architecture using the Redux framework for my data layer and Mustache templates for my view layer.
Before I go on, a brief definition of terms is required. SDG Systems’ Barcode List Manager application allows you to scan barcodes on your Android device that are organized into lists. Those lists can then be saved and exported in a variety of formats. Firebase is a real-time database owned by Google that communicates with your application over websockets. Flux architecture is a way of organizing code for client side web applications. Redux is a framework for implementing Flux architecture. Finally, Mustache is a templating language with support for several different programming languages.
When I first read about Facebook’s Flux architecture, I thought they were simply trying to make waves about renaming components in a Model View Controller (MVC) style architecture. After reading their explanation a few more times, it dawned on me that the real insight was not one of code organization but one of how data flows through an application. Obviously, organizing your code into logical chunks is still important, but Flux architecture enforces a strict unidirectional flow of data throughout the application, which ends up making the resulting solution much easier to reason about and therefore maintain and extend.
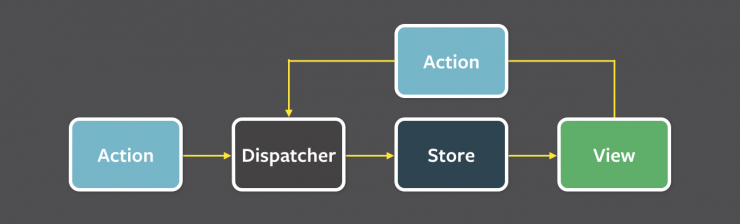
When implementing Flux within your application, start with a store where your data will be housed. Even though data in Firebase can be accessed in near real time, I think it makes sense to keep some separation between Firebase data and your application state. Redux tries to adhere to functional programming principles so the store functionality is replaced by a reducer that, when triggered by an action, computes a new state for the application based on the previous state of the data and the action that was performed. To instantiate the reducer, you can provide the initial state of the data. My application shows a list of barcodes scanned from the Barliman app along with metadata such as location coordinates and a timestamp and links the barcodes to a list of item names that the barcodes represent. This makes our reducer and initial state look like this:
// reducer (store in flux parlance) function barlimanApp(state, action) { switch (action.type) { // logic to compute a new state based on the action performed } } var initialState = { barcodes: [], activeBarcode: 0, itemNames: {}, editItemName: "" }; var store = Redux.createStore(barlimanApp, initialState);
The data elements are empty initially because they have to wait for the connection to Firebase to be established. Once we have our reducer/store setup, we then write some functions to read the state of our data from the store and display it to the user. Within the Redux framework, these view functions can subscribe to the result of the reducer/store every time it is run. The subscription doesn’t pass any parameters to the view function, so instead of relying on a global store variable, I wrapped my view functions inside of a closure so that every time the view function is run it still has access to the store passed to it when it was created. Typically, your view would check the new state against the previous state and determine if any work actually needs to be performed to reflect the new state.
function barcodeList(store) { return function() { // get the current state of the data var state = store.getState(); // UI code displaying our barcode data }; } var view = barcodeList(store); // when we subscribe our view to a store’s data updates we receive back a function // to unsubscribe the view from the store var view_unsubscribe = store.subscribe(view); // since the initial state is already populated and we want the user to see something we // need to run our view manually at first, subsequent data changes will automatically // rerun our view code view();
Now that the view is in place, we need to define some actions the user can perform on our data. These actions are used by our reducer/store to compute a new state of the data. Within Redux, these actions are objects that must contain a type attribute and can contain other parameters as well. Be careful to note what extra parameters are being passed along since you will want to unpack them inside of your reducer/store function. Anything can trigger actions, although typically actions are initiated by the user. In my application, since updates to the Firebase data can be subscribed to, I have actions defined for both the user and when Firebase publishes updates to the data. For our example, we want the user to be able to change the barcode being examined, so we would create an action like this:
// a constant that can be used in the main switch statement of our store var CHANGE_ACTIVE_BARCODE = "CHANGE_ACTIVE_BARCODE"; // a convenience function to generate the action object function changeActiveBarcode(index) { return { // the action the user has performed type: CHANGE_ACTIVE_BARCODE, // an extra parameter we pass along with the action index: index }; }
With an action defined, we have come full-circle around the unidirectional data flow of our application. Our store is instantiated with some initial data, that data is read by the view(s) to render the user interface, from the user interface the user can perform a set of clearly defined actions that are then used by the store to compute the new state of the application which when computed alerts the views and the cycle continues around the loop.
What are the advantages to this approach? As stated earlier, I agree with Facebook’s assertion that applications built with the Flux architecture are easier to reason about. Since all data flows through the same pipeline you don’t have to go hunting for the right model or controller that manipulates a particular piece of data. Also, since all of our user interactions are clearly defined within objects generated by helper functions that allows us to test our application without needing to worry about simulating user actions through the DOM. In the case of my application, it means that I can script out some actions to be run continuously to allow someone to present the features of the demo application without needing to interact directly with the application. Also, since I can subscribe to data updates in Firebase, I merely need to define some actions to determine how data updates are handled in my application.
So the next time you want to build a simple and maintainable application that can scale, give Flux with Redux a try and watch as your life as a developer becomes easier.
*Note: We have since renamed Barliman to "Data List Manager" because it now supports NFC in addition to barcode scanning.